
二级指针在单链表中的应用首先,我们有这样一个单链表的数据结构:
typedef struct ListNode{ int data; struct ListNode *next;}ListNode;
依据这样一个数据结构,假定我们创建了一个如下所示的一个单链表:
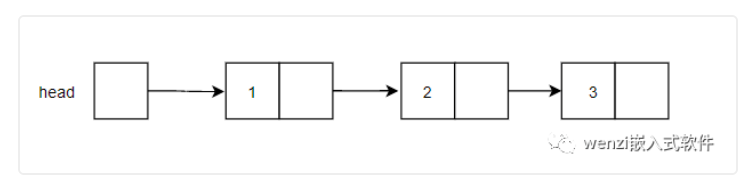
单链表
那么我们如果要删除链表中的一个结点的时候,第一时间采用的可能是如下所示的代码:
ListNode *find_and_delete(ListNode *head,int target){ ListNode *pre = NULL; ListNode *entry; for (entry = head; entry != NULL; entry = entry-》next) { if (entry-》data == target) { /* 判断删除的结点是否是第一个结点*/ if (entry == head) head = entry-》next; else pre-》next = entry-》next; free(entry); break; } pre = entry; } return head;}
上述代码所述的删除结点的思路遵循如下图所示的原理,首先是关于当所要删除的结点是第一个结点的时候,删除结点示意图如下所示:
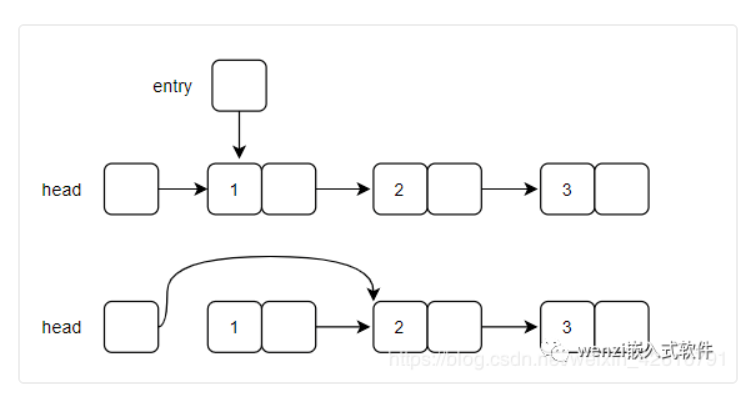
第一个结点删除原理
如果要删除的结点不是处在第一个结点的位置,那么删除结点的原理示意图如下图所示:
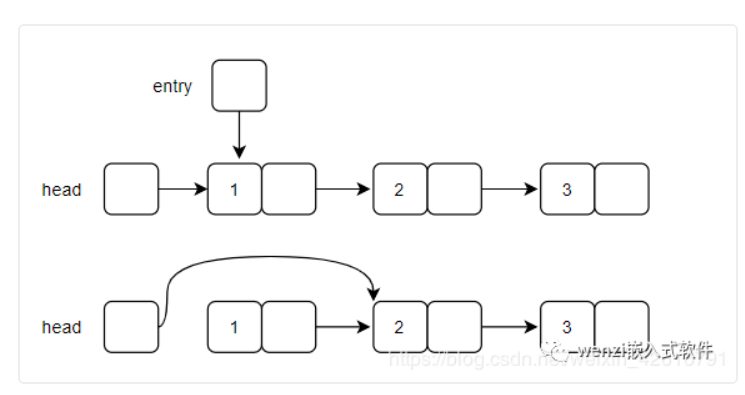
普通结点删除
上述就是一个使用一级指针操作链表的一个简单地例子,自己在理解这个例子的时候,也存在几个对我来说的难点,笔者写下来和大家分享一下,首先,
第一个难点就是头指针,在图中画的头指针指向了第一个结点,图中所示的头指针并没有数据域,只是单单地指向了第一个结点,在代码中的 head 指针变量却有数据域,并且就是第一个结点的数据,这个概念的理解其实是对于指针的理解,head 指向了第一个结点,一定注意在这里的 head 是头指针,并不是头结点。(这是笔者个人的理解,如果大家有不同的看法,欢迎各位朋友添加笔者微信共同探讨)。









