
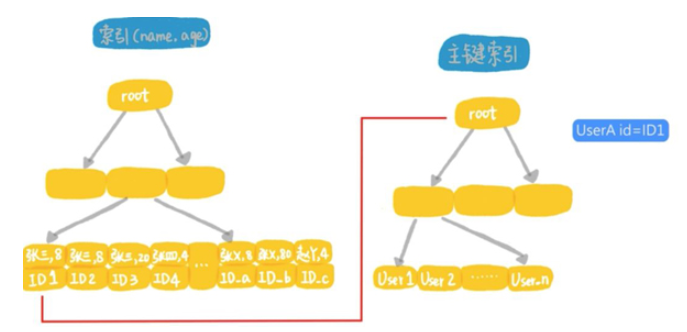
首先从联合索引上找到第1个年龄字段是张开头的记录,取出主键id,然后到主键索引树上,根据id取出整行的值;
判断年龄字段是否等于8,如果是就作为结果集的一行返回,如果不是就丢弃。
在联合索引上向右遍历,并重复做回表和判断的逻辑,直到碰到联合索引树上名字的第1个字不是张的记录为止。
我们把根据id到主键索引上查找整行数据这个动作,称为回表。你可以看到这个执行过程里面,最耗费时间的步骤就是回表,假设全国名字第1个字是张的人有8000万,那么这个过程就要回表8000万次,在定位第一行记录的时候,只能使用索引和联合索引的最左前缀,最称为最左前缀原则。
你可以看到这个执行过程,它的回表次数特别多,性能不够好,有没有优化的方法呢?
在MySQL5.6版本,引入了index condition pushdown的优化。我们来看看这个优化的执行流程:
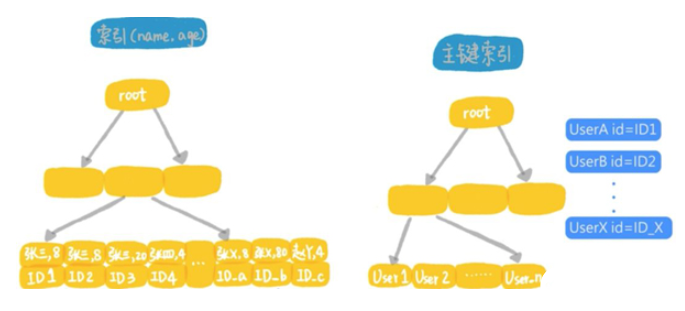
首先从联合索引树上,找到第1个年龄字段是张开头的记录,判断这个索引记录里面,年龄的值是不是8,如果是就回表,取出整行数据,作为结果集的一部分返回,如果不是就丢弃;
在联合索引树上,向右遍历,并判断年龄字段后,根据需要做回表,直到碰到联合索引树上名字的第1个字不是张的记录为止;
这个过程跟上面的差别,是在遍历联合索引的过程中,将年龄等于8的条件下推到所有遍历的过程中,减少了回表的次数,假设全国名字第1个字是张的人里面,有100万个是8岁的小朋友,那么这个查询过程中在联合索引里要遍历8000万次,而回表只需要100万次。









