
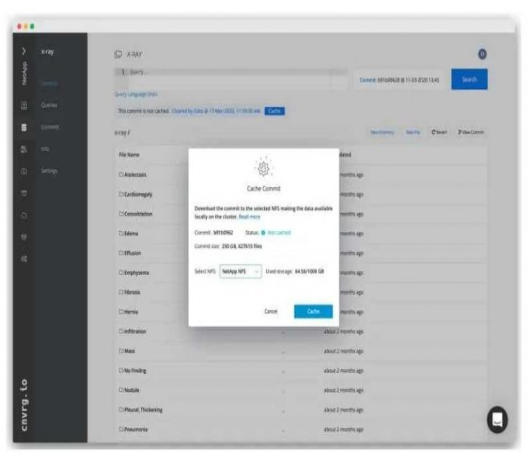
多云数据集移动性 –使用本地缓存作为数据的控制点。
Cnvrg.io和Netapp
NetApp AI和数据工程高级技术总监Santosh Rao说:“ 深度学习工作负载是独特的,因为它们需要访问可能来自不同数据源和分散位置的大型数据集中的随机数据样本。” “ 此外,深度学习需要接近GPU计算集群的高性能数据,这需要结合高性能闪存存储系统,边缘,核心和云的连接器以实现分散的数据位置访问,并支持NFS广泛使用的数据源格式或统一数据平台上的其他文件系统。NetApp与cnvrg.io建立了首个同类合作伙伴关系,旨在通过深度学习来改变其业务,从而将这些功能带给全球客户。“
cnvrg.io首席执行官兼联合创始人Yochay Ettun说:“ 我们与NetApp的合作关系提高了数据团队的生产力和效率。“ 我们很高兴推出用于ML的数据集缓存,以便为NetApp用户和cnvrg.io用户提供更快,更简化的访问权限,并提供高级数据管理和数据版本控制功能的工具,使数据团队可以专注于数据科学技术复杂性。“
关于存储技术就介绍完了,您有什么想法可以联系小编。









