
为了介绍 Aurora,我们先来简单看一下通常 Distributed Consensus 是如何做到 Strong Consistency 的。
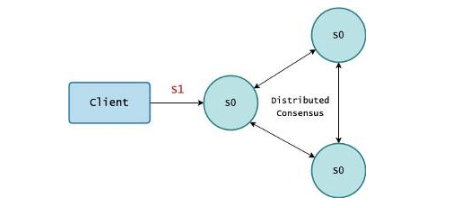
我们假设当前计算端的状态是 S0,此时我们收到了一个请求,要把状态变更为 S1。为了完成这个变更,存储端会发起了一次 Distributed Consensus。如果成功,则计算端把状态变更为 S1;如果失败,则状态维持在 S0 不变。可以看到存储端向计算端返回的状态只有成功和失败两个状态,而实际上存储端内部会有更多的状态,例如 5 个节点里面 3 个成功了,1 个失败了,1 个超时了。而这些状态都被存储端屏蔽了,计算端不感知。这就导致计算端必须等待存储端完成 Distributed Consensus 以后,才能继续向前推进。在正常情况下不会有问题,但一旦存储端发生异常,计算端必须要等待存储端完成 Leader Election 或 Membership Change,导致整个计算端被阻塞住。
而 Aurora 则打破了这个屏障。Aurora 的计算端可以直接向存储端发送写请求,并不要求存储端节点之间达成任何的 Consensus。
典型的 Aurora 实例包含 6 个存储节点,分散在 3 个 AZ 中。每个存储节点都维护了 Log 的列表,以及 Segment Complete LSN(SCL),也就是已经持久化的 LSN。存储节点会将 SCL 汇报给计算节点。计算节点会在 6 个节点中,找出 4 个最大的 SCL,并将其中最小的值作为 Protection Group Complete LSN(PGCL)。而 PGCL 就是 Aurora 实例已经达成 Consistency Point。
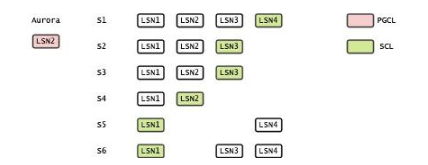
看上去好像和 Multi-Paxos 也有些相似?是的,但 Aurora 并不要求存储节点之间达成任何的 Consensus,发生故障的时候,存储节点不需要参与 Leader Election,也不需要等待所有的日志复制完成。这意味着计算节点基本上永远不会被阻塞。
Aurora 的精妙之处在于把 Distributed Consensus 从存储节点中抽离出来了,存储节点只是单纯的负责存储工作就好了,而 Consensus 由计算节点来完成。那这样看上去好像又和 PacificA 很相似?是的,我认为在整体思路上,Aurora 和 PacificA 是非常相似的。我个人认为 Consensus 和存储节点的解耦会是未来的一个趋势。









