
随着现代数据中心的发展,新的应用形态(Cloud-native、DevOps、Micro Service等)都要求基于云平台构建(Cloud-native),这对存储体系结构又有了新的要求,这些要求主要体现在以下几个方面。
面向服务的存储配置: 过去基于一个物理服务器或虚拟机配置存储卷的技术、依赖于FCoE、iSCSI等协议的技术已经落后了。
卷服务粒度更细、数量更多: 在最现代化的服务模型中,如NoSQL和消息队列,通常被设计成大规模扩展方式。他们部署时需要存储支持更多卷数量、更小的卷容量。而不像过去,一个计算节点通常映射一个大容量卷来提供数据库等应用。
存储本地多层化: 目前服务器至少有两个存储层级。基于全球客户服务器采购的实际情况来看,数据中心的服务器来自不同的供应商的多种服务器,不同服务器具有不同的内部容量层。客户希望新的存储结构来理解这些变化和不同,并能自动利用不同存储提供存储服务。
存储超融合化: 新服务架构要求数据计算和存储融合。以Hadoop为例,在计算是派遣到服务节点上运行的主机数据。
多服务颗粒存储操作: 新型应用程序不是单一的堆栈。而是通过部署在多个节点上的分布式模块进行业务交互组成。企业存储的操作,如快照、检查点还原、复制、配额等,需要提供服务堆栈级别上的支持。所以,我们的存储系统需要能意识到一组分布式x86服务器通过以太网织物绑在一起。
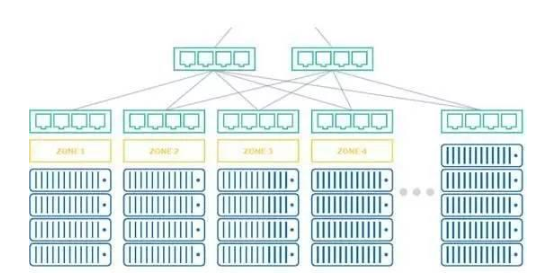
在数据中心中,硬件结构的现状一般是,来自不同供应商的服务器各自为政,不同存储容量和不同类型的服务器并存,Top of Rack交换机的能力也不同,而运行其上的软件是以一个更高的粒度,通过松耦的一组容器化服务运行在不同节点上。那么,我们该如何扩展存储层来与大量相对较薄的服务一起工作呢,当然,常用的做法就是将堆栈拆分成独立的数据可用区和计算区,根据不同SAL的应用需求匹配相应的存储资源。
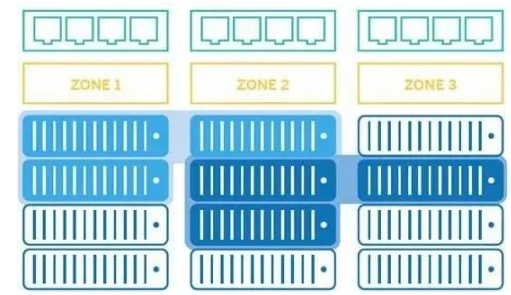
实质上,上图就是一个容器感知存储架构,该架构要实现如何根据存储需求将数据放置在容器的位置区。这种架构可以支撑一个更大的容器计算集群,同时可以保持存储的性能和时延要求。
面对更细粒度的、自恢复和可发现的面向服务的应用架构,存储也不应该有任何核心的集中元数据服务器,元数据应该分布式存放和去中心化存放,并通过负载均衡等算法或检测协议(Gossip Protocol)实现高效的故障自愈系统和高可靠系统。









