
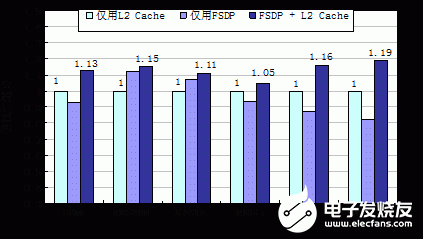
图7 三种数据映射方式下系统的计算性能对比
实验结果表明,在FSDP + L2 Cache方式下,程序的性能是最高的。6组程序的平均性能加速比为1.13。本文分析认为:
对于核间共享数据包含大量细粒度数据和不规则数据流的应用程序(例如PEGWIT和RASTA),仅用FSDP相比仅通过L2 Cache传输共享数据具有更高的计算性能;
对于核间共享数据量较大和数据流分布比较密集的应用程序(例如2MP3_d和MPEG2_e),仅用FSDP传输共享数据的计算性能较低,这是因为FSDP对共享数据的分块处理使得同步开销在执行时间中的比例增大,影响了总执行时间;
FSDP与共享数据Cache结合使用进一步提高了共享存储多核DSP的片内数据重用性,减少了对片外数据的长延迟访问,因而能够获得最佳的计算性能。其中,对于需要紧耦合共享的小容量数据或者非常不规则的短数据流,优先选择通过FSDP传输,减少通过共享Cache的长延迟访问开销;反之,对于大块数据的共享或者规则数据流的传输,则宜采用共享Cache的方式,降低数据频繁分块的同步开销。
5.3 扩展性分析
在消除了FSDP的访问冲突之后,所有DSP核可以同时访问不同的存储体。理论上来看,FSDP的访问带宽可以随着DSP核数量的增长而线性增长,具有良好的可扩展性。为此,我们进行了分析与实验。定义B为FSDP的有效访问带宽,即在考虑访存延迟和工作频率的情况下所有DSP核访问FSDP的实际存储带宽;N表示DSP核的数量。本文在N=1~8的情况下分别对FSDP进行了单独的设计实现,得到了B与N的关系,如图8所示。
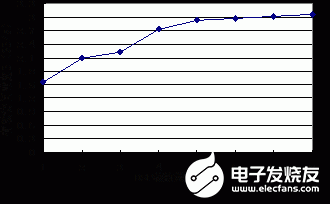
图8 FSDP有效访问带宽与DSP核数量的关系
由实验结果可见,当N小于5时, B快速增长,与N呈近似的线性关系。随着N的进一步增大,DSP核与存储体之间的控制逻辑开销、互连总线和交叉开关端口数量以O(N2)量级增长,FSDP的工作频率开始下降,访问延迟越来越大,FSDP的有效访问带宽增长十分缓慢。因此,FSDP更适合于5核以内的多核DSP。当DSP核数量超过8核以上时,我们将以4核为一个超节点进行结构扩展。超节点内部采用FSDP实现紧耦合的数据传输,超节点之间通过片上网络(NoC)或者其他共享存储结构进行数据传输。
7 结束语
相比传统的Cache结构,便笺式存储器具有更灵活的结构、简洁的控制逻辑、更低的访问延迟和方便的数据管理等诸多优势。本文针对多核DSP架构设计的快速共享数据缓冲池FSDP结合了便笺式存储器的结构特点和共享存储结构的编程需要,采用软/硬件联合的设计方法,为多核DSP之间传输细粒度共享数据提供了一个紧耦合的快速通路,相比共享二级Cache和DMA传输方式具有更好的传输效率,是一种新型而实用的、可扩展多核共享存储结构。今后,我们将深入研究面向多核处理器的高性能共享存储结构,增强片上存储的可扩展性和可重构能力,进一步提高多核SoC的存储带宽。









