
本文采用SMIC 0.13μm CMOS工艺库对FSDP进行了设计实现。其中各存储体采用EDA工具生成的单端口SRAM。下表2给出了FSDP的各项设计指标。其中,“无阻塞读延迟”是指在同步成功且没有冲突的情况下,从DSP核发出读请求到获得返回数据之间的时间间隔。
表2 0.13μm CMOS工艺下四通道FSDP的各项性能指标

5.2 性能对比
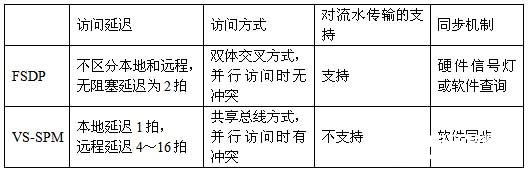
对于多核处理器共享SPM的研究,前人的工作主要是针对SPM的编译优化和数据划分算法的研究。文献0介绍的VS-SPM(虚拟共享便笺存储器)原型结构与本文的FSDP有类似之处,它根据SPM与处理器核的关系,将SPM分成本地SPM和远程SPM,各个处理器核通过共享总线访问各SPM模块。下表3对比了本文的FSDP与VS-SPM在结构上的差异。VS-SPM主要是针对编译优化和数据划分算法优化而设计的,其硬件优化程度和访问速度都不及FSDP,而且没有解决多个处理器核并行访问冲突的问题,不支持核间数据的流水传输。
表3 FSDP与VS-SPM的结构对比
本文建立了VS-SPM的结构模型,将DSP核间同样一批共享数据先后映射到VS-SPM和FSDP的存储空间上,分别得到两种结构下程序的执行时间TVS-SPM和TF-SDP,然后按照(1)式计算出FSDP相对VS-SPM的性能加速比。

图6给出了6组测试程序的实验结果。结果表明,通过FSDP在DSP核之间传输共享数据相比通过VS-SPM传输具有明显的性能优势,6组程序的平均性能加速比达到了1.37。
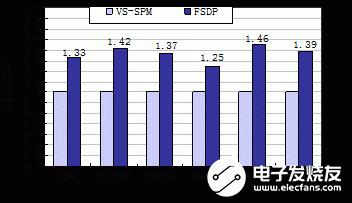
图6 FSDP相对VS-SPM的性能加速比
在引入FSDP之前,异构多核DSP主要通过共享L2 Cache传输DSP核间的共享数据。为了评测FSDP对系统性能的加速作用,本文比较了下列三种数据映射方式下异构多核DSP的计算性能:
仅用L2 Cache:DSP核间的共享数据全部通过L2传输;
仅用FSDP:DSP核间的共享数据全部通过FSDP传输;
FSDP + L2:将DSP核间的不规则共享数据映射到FSDP的地址空间,其余的共享数据流仍通过L2传输。
利用SDSP-Sim软件模拟器分别得到上述三种映射方式下程序的执行时间,然后以第一种映射方式下的执行时间为基准,计算出另外两种方式的性能加速比,结果如图7所示:









